はじめに
Raspberry Pi3B + Pi Camera V2.1 で物体検知をしてみます。
主な手順やソースコードは ChatGPT(o4-min-highモデル)によるもので、そのまま実行できなかった部分を調整して実施しています。
ハードウェア
Raspberry Pi3B はだいぶ前に購入したもので、Cameraは今回新たに購入しました。(Amazonにて3,180円)

カメラを固定しないと作業がしづらいので、少し雑ですが、タッパー容器を加工してケースにしました。



準備
接続確認
Pi Camera V2.1(imx219)が認識されていることを確認します。
$ sudo dmesg | grep imx
[ 0.078042] /soc/csi@7e801000: Fixed dependency cycle(s) with /soc/i2c0mux/i2c@1/imx219@10 [ 0.078123] /soc/i2c0mux/i2c@1/imx219@10: Fixed dependency cycle(s) with /soc/csi@7e801000
full-upgrade
full-upgradeします。(しばらく時間がかかります)
$ sudo apt udpate $ sudo apt full-upgrade
python3-opencv
python3-opencv をインストールします。
sudo apt update sudo apt install -y python3-opencv
libcamera-hello
libcamera-hello を実行してカメラの画像が確認できました。
$ libcamera-hello
Python picamera2 を使ったPreview
下記のプログラムにてPreviewを試しました。
import time from picamera2 import Picamera2, Preview picam2 = Picamera2() picam2.start_preview(Preview.DRM) picam2.start() time.sleep(30) picam2.stop_preview() picam2.stop()
下記のメッセージが表示され、プレビューが表示されません。
$ python3 preview.py
[0:17:04.530956848] [2006] INFO Camera camera_manager.cpp:326 libcamera v0.5.0+59-d83ff0a4
[0:17:04.588985200] [2009] WARN RPiSdn sdn.cpp:40 Using legacy SDN tuning - please consider moving SDN inside rpi.denoise
[0:17:04.594611024] [2009] INFO RPI vc4.cpp:447 Registered camera /base/soc/i2c0mux/i2c@1/imx219@10 to Unicam device /dev/media2 and ISP device /dev/media0
[0:17:04.594944703] [2009] INFO RPI pipeline_base.cpp:1121 Using configuration file '/usr/share/libcamera/pipeline/rpi/vc4/rpi_apps.yaml'
[0:17:04.627762047] [2006] INFO Camera camera.cpp:1205 configuring streams: (0) 640x480-XBGR8888 (1) 640x480-SBGGR10_CSI2P
[0:17:04.628871515] [2009] INFO RPI vc4.cpp:622 Sensor: /base/soc/i2c0mux/i2c@1/imx219@10 - Selected sensor format: 640x480-SBGGR10_1X10 - Selected unicam format: 640x480-pBAA
commit failed
commit failed
Ctrl + Alt + F1 で tty(tty1) に切り替えた環境で実行することで、プレビューが表示されました。

Python仮想環境
このあとの作業で、OSの環境に直接pipインストールしたくない場合には、Pythonの仮想環境を作成して実行します。 ただし、下記のように作成すると、cv2 が無いというエラー (ModuleNotFoundError: No module named ‘cv2’) が発生します。
python -m venv venv
–system-site-packages を指定して仮想環境を作成します。
python -m venv --system-site-packages venv
. venv/bin/activate
(参考)
人物検知 (haarcascades)
ソースコード
https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_fullbody.xml からxmlファイルをダウンロードし、下記プログラムを実行しました。
#!/usr/bin/env python3 import time import cv2 from picamera2 import Picamera2 def main(): picam2 = Picamera2() config = picam2.create_preview_configuration( main={"size": (640, 480)}, lores={"size": (160, 120)}, display="main" ) picam2.configure(config) picam2.start() # ② Haar Cascade の読み込み cascade_path = "./haarcascade_fullbody.xml" # cascade_path = "./haarcascade_fullbody.xml" cascade_path = "./haarcascade_eye.xml" # cascade_path = "./haarcascade_frontalface_default.xml" body_cascade = cv2.CascadeClassifier(cascade_path) cv2.namedWindow("Detection", cv2.WINDOW_NORMAL) try: while True: # ③ フレーム取得(NumPy 配列) frame = picam2.capture_array("main") # BGR8888 の ndarray # ④ グレースケール変換&検知 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) bodies = body_cascade.detectMultiScale( gray, scaleFactor=1.1, minNeighbors=3, minSize=(60, 60) ) # ⑤ 検知結果を描画 for (x, y, w, h) in bodies: cv2.rectangle(frame, (x, y), (x+w, y+h), (0,255,0), 2) # ⑥ ウィンドウ表示 cv2.imshow("Detection", frame) # Esc キーで終了 if cv2.waitKey(1) & 0xFF == 27: break finally: picam2.stop() cv2.destroyAllWindows() if __name__ == "__main__": main()
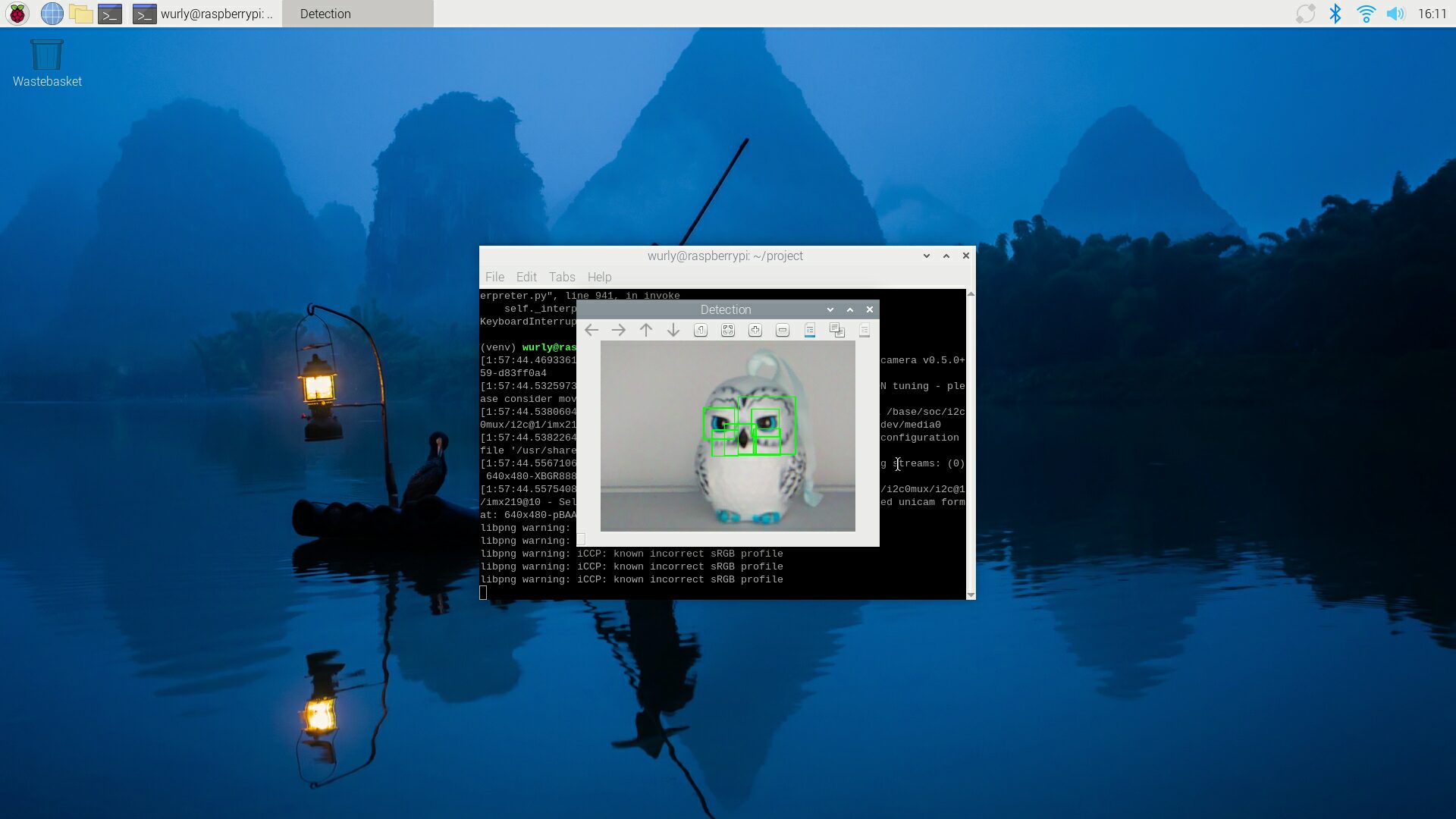
検出結果
haarcascade_eye.xml を使用することで、目を検出しています。
ただ、目以外のところも検出しちゃっていますね。。
人物検知 (tflite)
tflite-runtimeのインストール
tflite-runtimeをインストールします。
pip3 install tflite-runtime
モデルのダウンロード
下記、「メタデータを含むスターターモデルをダウンロードする」より、1.tflite をダウンロードします。
https://www.tensorflow.org/lite/models/object_detection/overview?hl=ja
そして、これを unzip すると labelmap.txt が出てきます。
$ unzip 1.tflite Archive: 1.tflite extracting: labelmap.txt
1.tflite と labelmap.txt をそれぞれ、detect.tflite” と “labels.txt” にrenameしてプログラムと同じ場所に置きます。
ソースコード
下記のプログラムを実行します。
#!/usr/bin/env python3 import cv2 import numpy as np import tflite_runtime.interpreter as tflite from picamera2 import Picamera2 # TFLite 用ヘルパー class TFLiteModel: def __init__(self, model_path, label_path, threshold=0.5): self.interpreter = tflite.Interpreter(model_path=model_path) self.interpreter.allocate_tensors() self.input_details = self.interpreter.get_input_details() self.output_details = self.interpreter.get_output_details() self.labels = [l.strip() for l in open(label_path)] self.threshold = threshold def detect(self, image): h, w, _ = image.shape inp_h, inp_w = self.input_details[0]['shape'][1:3] img = cv2.resize(image, (inp_w, inp_h)) input_data = np.expand_dims(img, axis=0) self.interpreter.set_tensor(self.input_details[0]['index'], input_data) self.interpreter.invoke() boxes = self.interpreter.get_tensor(self.output_details[0]['index'])[0] # [N,4] classes = self.interpreter.get_tensor(self.output_details[1]['index'])[0] # [N] scores = self.interpreter.get_tensor(self.output_details[2]['index'])[0] # [N] results = [] for box, cls, score in zip(boxes, classes, scores): if score < self.threshold or int(cls) >= len(self.labels): continue ymin, xmin, ymax, xmax = box results.append({ "label": self.labels[int(cls)], "score": float(score), "rect": ( int(xmin * w), int(ymin * h), int((xmax - xmin) * w), int((ymax - ymin) * h) ) }) return results def main(): # カメラ picam2 = Picamera2() config = picam2.create_preview_configuration( main={"size": (640, 480), "format": "RGB888"}, # ←ここで3チャンネル指定 display="main" ) picam2.configure(config) picam2.start() # TFLite モデル読み込み model = TFLiteModel("detect.tflite", "labels.txt", threshold=0.6) cv2.namedWindow("TFLite Detection", cv2.WINDOW_NORMAL) try: while True: frame = picam2.capture_array("main") results = model.detect(frame) # 描画 for r in results: x, y, w, h = r["rect"] cv2.rectangle(frame, (x,y), (x+w,y+h), (255,0,0), 2) cv2.putText(frame, f'{r["label"]}:{r["score"]:.2f}', (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,0,0), 2) cv2.imshow("TFLite Detection", frame) if cv2.waitKey(1) & 0xFF == 27: break finally: picam2.stop() cv2.destroyAllWindows() if __name__ == "__main__": main()
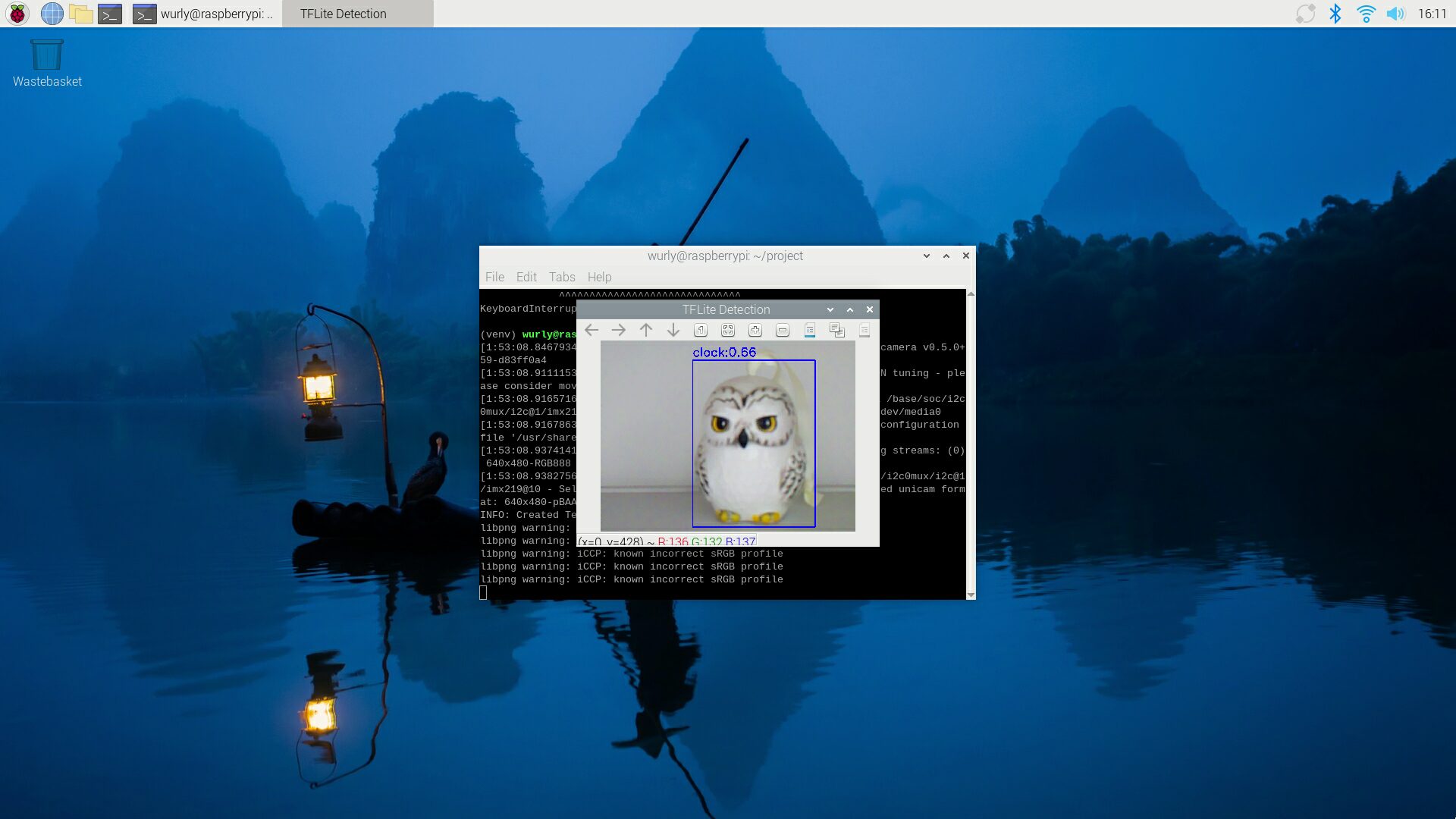
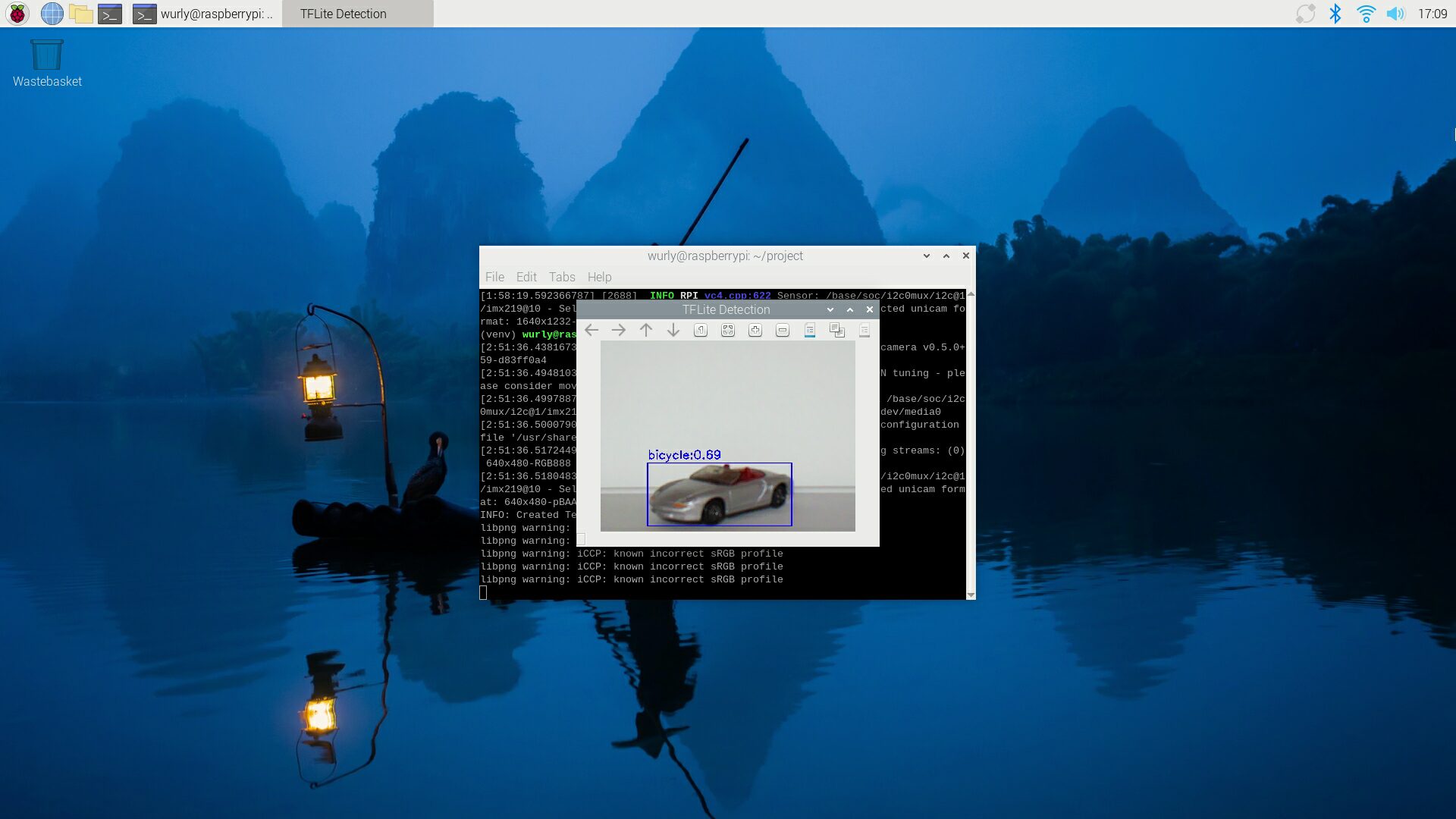
検出結果
物体としては検出できていますが、フクロウ(Hedwig)の置き物がclockとして検出されてしまっています。
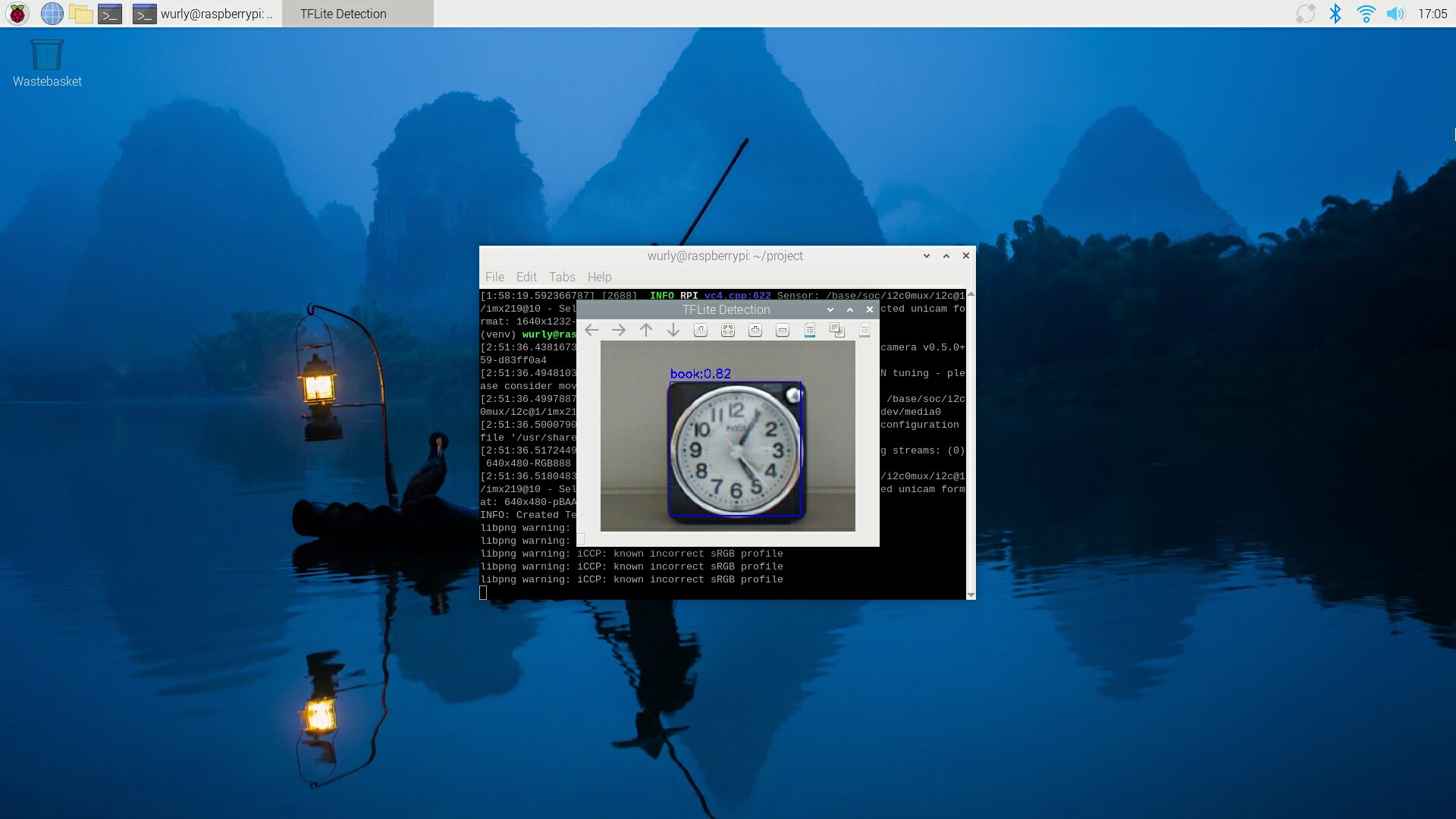
一方で時計は book として検出。
ミニカーは bicycle として検出されました。。
おわりに
Raspberry Pi3B + Pi Camera V2.1 でサンプルのモデルを使用して物体検出を行いました。
物体の検出自体はできたものの、物体の識別はうまくいきませんでした。
モデルのトレーニングや、パラメータの設定等が必要となるものと思われます。