はじめに
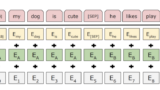
上記ページで公開されているDocker ImageとJupyter Notebook用のPythonコードを使用させていだだき、日本語BERTを試しました。
dockerコンテナの実行
docker pull
$ docker pull ishizakiyuko/japanese_bert_trial:1.0.1 1.0.1: Pulling from ishizakiyuko/japanese_bert_trial Digest: sha256:7d3aaf385e7c2ecc810eaf96098bb522b945fcdeb70e104e0a5cc3e3a8fd7182 Status: Downloaded newer image for ishizakiyuko/japanese_bert_trial:1.0.1 docker.io/ishizakiyuko/japanese_bert_trial:1.0.1
docker image ls
$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE ishizakiyuko/japanese_bert_trial 1.0.1 0d5c7dc32e9d 3 years ago 10.5GB
docker run
Dockerコンテナを起動します。
$ docker run -p 8888:8888 -d ishizakiyuko/japanese_bert_trial:1.0.1
docker container ls
コンテナIDを確認します。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e0ba28ed92ee ishizakiyuko/japanese_bert_trial:1.0.1 "/bin/sh -c '/opt/co…" 50 seconds ago Up 50 seconds 0.0.0.0:8888->8888/tcp, :::8888->8888/tcp musing_jang
docker logs
上記で取得したコンテナIDを使用してlogを取得します。
token は c909ce4c1770455b12e6ef46d4b13ef7733190affe22b510 であることが確認できます。
$ docker logs e0ba28ed92ee [I 02:23:09.614 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret [I 02:23:09.730 NotebookApp] Serving notebooks from local directory: /home/jovyan [I 02:23:09.730 NotebookApp] The Jupyter Notebook is running at: [I 02:23:09.730 NotebookApp] http://e0ba28ed92ee:8888/?token=c909ce4c1770455b12e6ef46d4b13ef7733190affe22b510 [I 02:23:09.730 NotebookApp] or http://127.0.0.1:8888/?token=c909ce4c1770455b12e6ef46d4b13ef7733190affe22b510 [I 02:23:09.730 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 02:23:09.733 NotebookApp] To access the notebook, open this file in a browser: file:///home/jovyan/.local/share/jupyter/runtime/nbserver-7-open.html Or copy and paste one of these URLs: http://e0ba28ed92ee:8888/?token=c909ce4c1770455b12e6ef46d4b13ef7733190affe22b510 or http://127.0.0.1:8888/?token=c909ce4c1770455b12e6ef46d4b13ef7733190affe22b510 [I 02:23:26.334 NotebookApp] 302 GET / (172.17.0.1) 0.48ms [I 02:23:26.338 NotebookApp] 302 GET /tree? (172.17.0.1) 0.78ms
ウェブブラウザの起動、Notebookの作成
ウェブブラウザの起動
$ google-chrome &
token を入れる
上記で取得したtokenを “Password or token:” のところに入力して “Log in” します。
ログイン後の画面
Notebookを作成
参考ページのコードの実行
コードの実行方法
スクリプトをブラウザ上のコードエリアに記載し、順次実行していきます。
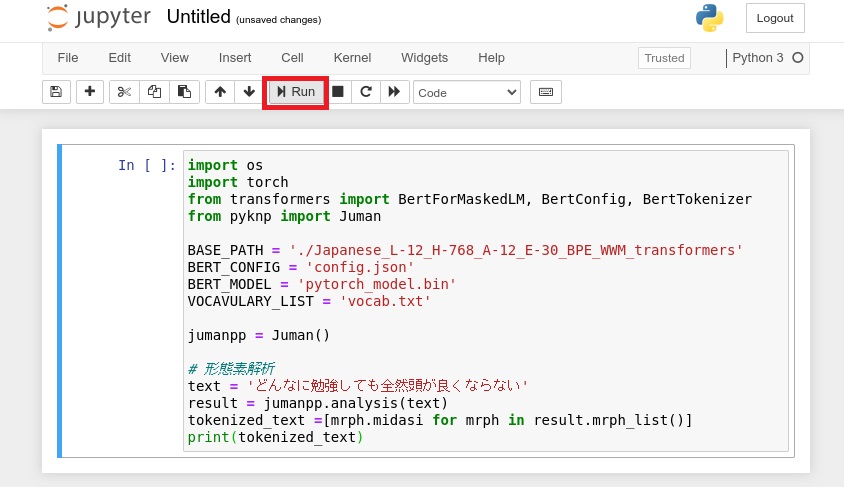
参考ページの内容を実行
下記のような内容となります。
どんなに勉強しても全然頭が良くならない
この文章において、「頭」という単語(トークン)をマスクして予測するという内容です。
下記は、参考にしたページで公開されているJupyter Notebook用のPythonコードです。
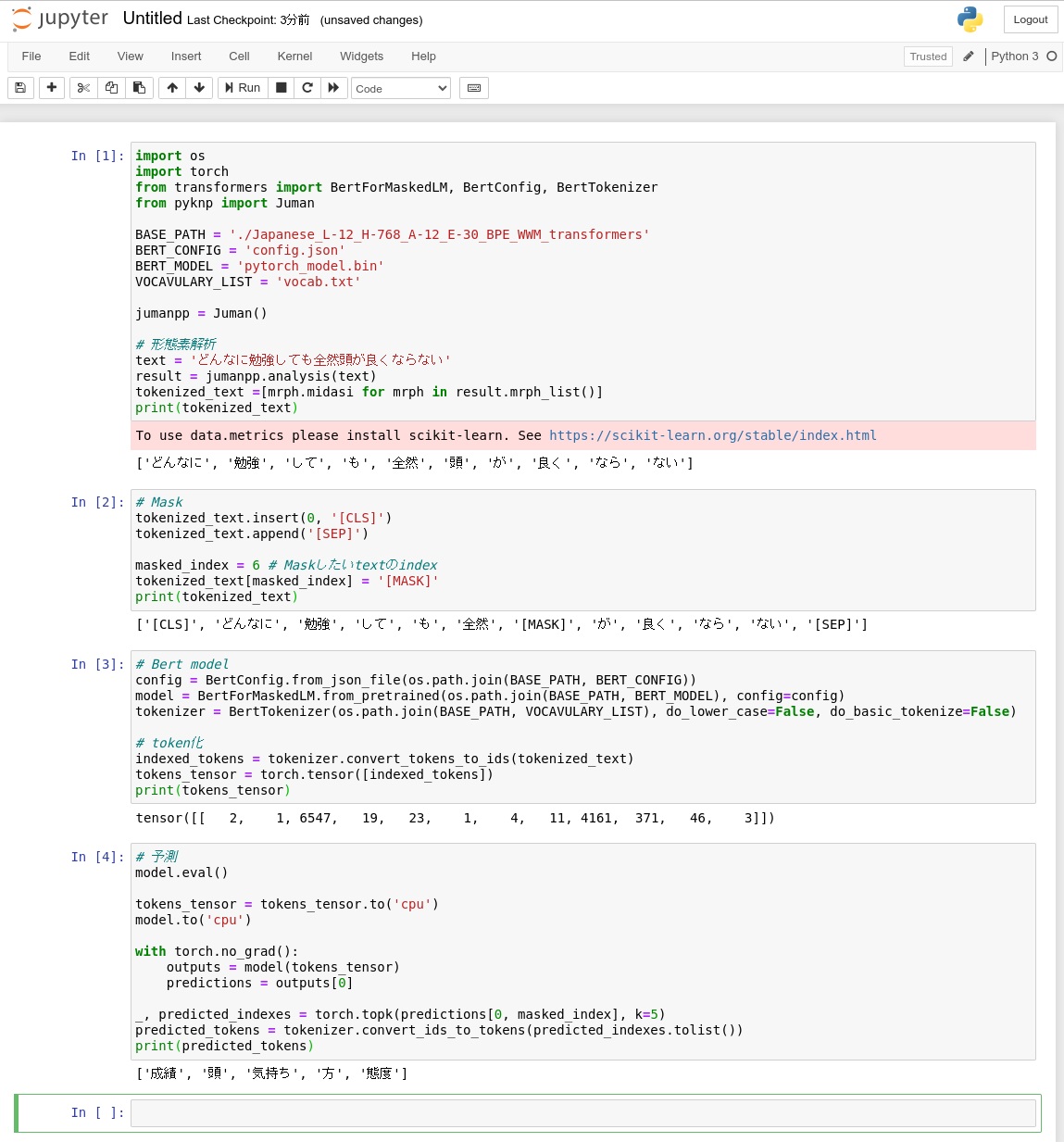
import os import torch from transformers import BertForMaskedLM, BertConfig, BertTokenizer from pyknp import Juman BASE_PATH = './Japanese_L-12_H-768_A-12_E-30_BPE_WWM_transformers' BERT_CONFIG = 'config.json' BERT_MODEL = 'pytorch_model.bin' VOCAVULARY_LIST = 'vocab.txt' jumanpp = Juman() # 形態素解析 text = 'どんなに勉強しても全然頭が良くならない' result = jumanpp.analysis(text) tokenized_text =[mrph.midasi for mrph in result.mrph_list()] print(tokenized_text)
# Mask tokenized_text.insert(0, '[CLS]') tokenized_text.append('[SEP]') masked_index = 6 # Maskしたいtextのindex tokenized_text[masked_index] = '[MASK]' print(tokenized_text)
# Bert model config = BertConfig.from_json_file(os.path.join(BASE_PATH, BERT_CONFIG)) model = BertForMaskedLM.from_pretrained(os.path.join(BASE_PATH, BERT_MODEL), config=config) tokenizer = BertTokenizer(os.path.join(BASE_PATH, VOCAVULARY_LIST), do_lower_case=False, do_basic_tokenize=False) # token化 indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text) tokens_tensor = torch.tensor([indexed_tokens]) print(tokens_tensor)
# 予測 model.eval() tokens_tensor = tokens_tensor.to('cpu') model.to('cpu') with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0] _, predicted_indexes = torch.topk(predictions[0, masked_index], k=5) predicted_tokens = tokenizer.convert_ids_to_tokens(predicted_indexes.tolist()) print(predicted_tokens)
下記の通り、実行できました。
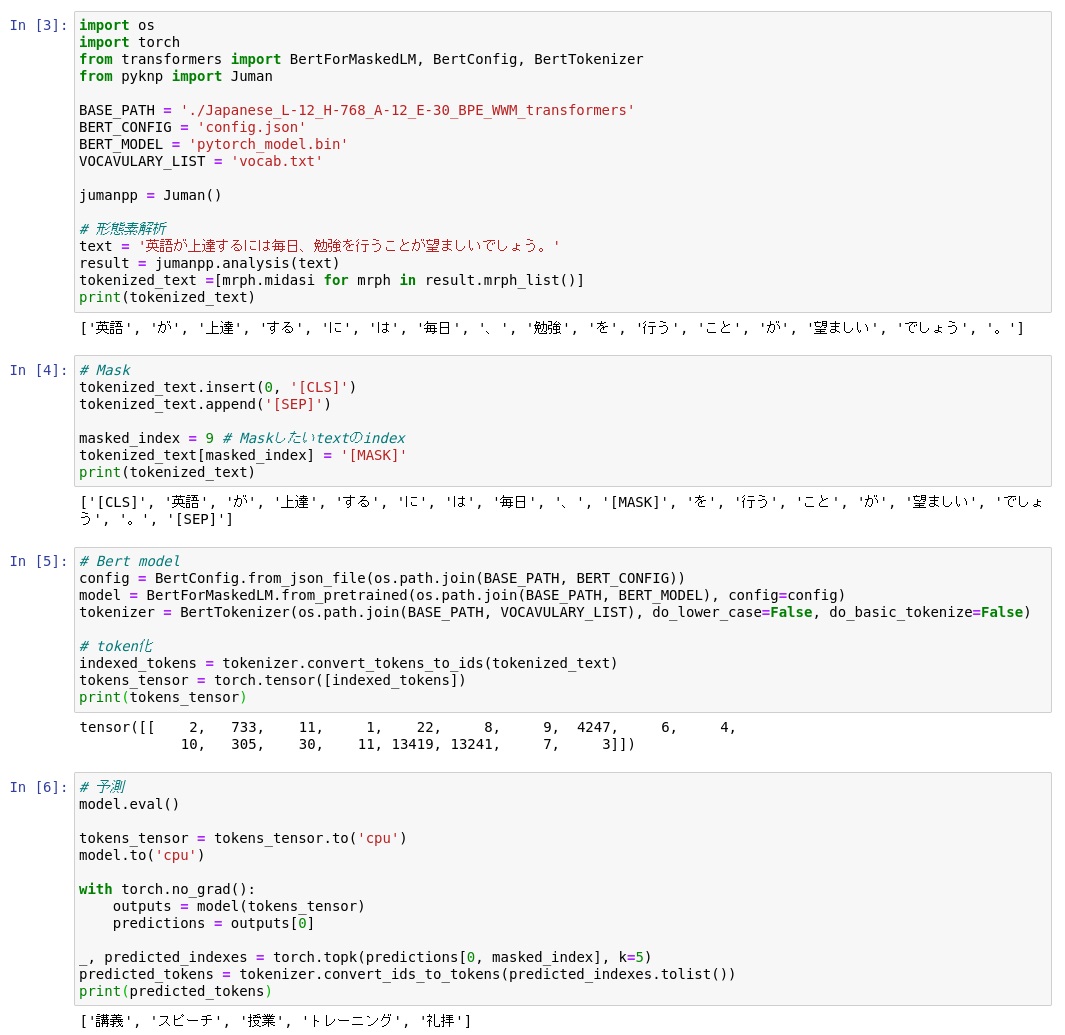
別のコードの実行
別の文章でお試し
別の文章で試しました。
英語が上達するには毎日、勉強を行うことが望ましいでしょう。
この文章において、「勉強」をマスクして予測してみます。
結果は、[‘講義’, ‘スピーチ’, ‘授業’, ‘トレーニング’, ‘礼拝’] となりました。
考察
- 元の文章
- 英語が上達するには毎日、勉強を行うことが望ましいでしょう。
- 予測された文章
- 英語が上達するには毎日、講義を行うことが望ましいでしょう。
- 英語が上達するには毎日、スピーチを行うことが望ましいでしょう。
- 英語が上達するには毎日、授業を行うことが望ましいでしょう。
- 英語が上達するには毎日、トレーニングを行うことが望ましいでしょう。
- 英語が上達するには毎日、礼拝を行うことが望ましいでしょう。
多くの日本人は元の文章は「学習者が」毎日「何か」を「行う」ことで英語が上達することを想定すると思われますので、この場合「トレーニング」又は「スピーチ」が適切と考えると思われますが、それなりの結果は得られました。
2023年現在では、ChatGPTが既に一般的に使われるようになっておりかつ実用レベルとなっていますが、2019年時点でもこれくらい手軽にAIによる自然言語処理がでできていたということがわかりました。