概要
WindowsでStable Diffusion 2.0を実行して画像生成を行います。
環境設定(インストール)については下記を参照ください。

グラフィックボードは ZOTAC GAMING GeForce RTX 2060 Twin Fan (Memory 6GB) を使用して試しました。(※現時点ではこのボードでStable Diffusion 2.0を画像を生成することはできていません。)
Stable Diffusion 2.0
git clone https://huggingface.co/stabilityai/stable-diffusion-2
python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
開始することはできたのですが、CUDA out of memory が発生し、画像は生成できませんでした。
D:\home\wurly\project_image_ai\stable_d2\stablediffusion>python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
Global seed set to 42
Loading model from ./stable-diffusion-2/768-v-ema.ckpt
Global Step: 140000
A matching Triton is not available, some optimizations will not be enabled.
Error caught was: No module named 'triton'
LatentDiffusion: Running in v-prediction mode
Setting up MemoryEfficientCrossAttention. Query dim is 320, context_dim is None and using 5 heads.
Setting up MemoryEfficientCrossAttention. Query dim is 320, context_dim is 1024 and using 5 heads.
(略)
Setting up MemoryEfficientCrossAttention. Query dim is 320, context_dim is None and using 5 heads.
Setting up MemoryEfficientCrossAttention. Query dim is 320, context_dim is 1024 and using 5 heads.
DiffusionWrapper has 865.91 M params.
making attention of type 'vanilla-xformers' with 512 in_channels
building MemoryEfficientAttnBlock with 512 in_channels...
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla-xformers' with 512 in_channels
building MemoryEfficientAttnBlock with 512 in_channels...
Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...
Sampling: 0%| | 0/1 [00:00<?, ?it/s]Data shape for DDIM sampling is (1, 4, 96, 96), eta 0.0 | 0/1 [00:00<?, ?it/s]
Running DDIM Sampling with 50 timesteps
DDIM Sampler: 0%| | 0/50 [00:07<?, ?it/s]
data: 0%| | 0/1 [00:14<?, ?it/s]
Sampling: 0%| | 0/1 [00:14<?, ?it/s]
Traceback (most recent call last):
File "D:\home\wurly\project_image_ai\stable_d2\stablediffusion\scripts\txt2img.py", line 289, in <module>
main(opt)
File "D:\home\wurly\project_image_ai\stable_d2\stablediffusion\scripts\txt2img.py", line 248, in main
samples, _ = sampler.sample(S=opt.steps,
File "C:\usr\Python310\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\models\diffusion\ddim.py", line 103, in sample
samples, intermediates = self.ddim_sampling(conditioning, size,
File "C:\usr\Python310\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\models\diffusion\ddim.py", line 163, in ddim_sampling
outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
File "C:\usr\Python310\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\models\diffusion\ddim.py", line 211, in p_sample_ddim
model_uncond, model_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\models\diffusion\ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\models\diffusion\ddpm.py", line 1329, in forward
out = self.diffusion_model(x, t, context=cc)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\diffusionmodules\openaimodel.py", line 776, in forward
h = module(h, emb, context)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\diffusionmodules\openaimodel.py", line 84, in forward
x = layer(x, context)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\attention.py", line 334, in forward
x = block(x, context=context[i])
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\attention.py", line 269, in forward
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\diffusionmodules\util.py", line 114, in checkpoint
return CheckpointFunction.apply(func, len(inputs), *args)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\diffusionmodules\util.py", line 129, in forward
output_tensors = ctx.run_function(*ctx.input_tensors)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\attention.py", line 272, in _forward
x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None) + x
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "d:\home\wurly\project_image_ai\stable_d2\stablediffusion\ldm\modules\attention.py", line 220, in forward
v = self.to_v(context)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "C:\usr\Python310\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
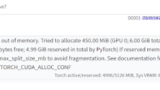
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 6.00 GiB total capacity; 5.23 GiB already allocated; 0 bytes free; 5.28 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解像度 512×512、384×384、256×256、128×128 いずれもNG。
python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 512 --W 512 python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 384 --W 384 python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 256 --W 256 python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 128 --W 128
–ckpt で 512×512 ベースモデルを指定してみましたが、これもNG。
wget https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt 512-base-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 128 --W 128
Stable Diffusion 2.1
再度、Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models を見直していたところ、
News の December 7, 2022 の Version 2.1 のところに、
To enable fp16 (which can cause numerical instabilities with the vanilla attention module on the v2.1 model) , run your script with ATTN_PRECISION=fp16 python <thescript.py>
との記載がありました。
実績として、Stable Diffusion 1.4では、fp16 を有効にすることで Graphic Memory 6GB でも画像生成できていました。 Stable Diffusion 2.1 を使用し、fp16 を有効することで CUDA Out of memory を回避できないかを探ります。
git clone https://huggingface.co/stabilityai/stable-diffusion-2-1
set ATTN_PRECISION=fp16
python scripts/txt2img.py --prompt "a girl eating curry with rice" --n_iter 1 --n_samples 1 --ckpt ./stable-diffusion-2-1/768-v-ema.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 384 --W 384
上記の通り試してみましたが、結果的には、画像生成はできていません。
Graphic Memory がもっと大きい別のグラフィックボードを導入して試したいと思います。
参考
Stable Diffusion 1.0 向けの内容のような気がします。

Stable Diffusion 1.0 向けの内容のような気がします。

“画像一枚でもpythonが11751MiBのGPUメモリを占有していたので12GBでギリギリ動かせている状況です。”とあり、6GB では厳しそうです。

512×512 モデルを取得する方法など参考になりました。